Java Streams filter 메서드 여러 번 사용 vs 조건 중첩하여 한 번 사용
Java Streams의 filter 메서드는 Predicate를 인자로 받아 false를 반환하는 element를 거르는 기능을 수행합니다.
예를 들어 모바일 기기의 요금제를 추천할 때,
- 시니어 요금제 중
- 5만원 이하이며
- 4G 네트워크 인 요금제를 찾는 코드를
Stream으로 작성하는 경우
1
2
public record Plan(Target target, int price, Network network) {
}
1
2
3
4
5
6
// 생략
List<Plan> recommendedPlans = planStream
.filter(plan -> plan.target() == Target.Senior)
.filter(plan -> plan.price() <= 50000)
.filter(plan -> plan.network() == Network.4G)
.toList();
이 될 것입니다.
당연하게도, 위 코드는 Predicate가 filter 메서드 3개로 나뉘어져 있기 때문에 가독성이 좋습니다. 시니어 요금제, 5만원 이하, 4G 네트워크가 순서대로 잘 읽힙니다.
그럼 다음 예시를 들어,
1
2
public record User(String name, int age, Gender gender) {
}
1
2
3
4
5
List<User> filteredUsers = userStream
.filter(user -> user.gender() == Gender.MALE)
.filter(user -> user.name().startsWith("이"))
.filter(user -> user.age() == 29)
.toList();
이 코드는 어떨까요? 물론 가독성이 뛰어납니다.
남자, 이씨 성, 29살인 user 리스트를 얻기 위해 필터링 하는 것이 순서대로 잘 읽힙니다.
하지만, recommendedPlans와 filteredUsers에는 큰 차이가 있습니다.
핸드폰 요금제의 경우, 보통 100가지를 넘지 않지만, 사용자의 경우 100만명, 1000만명, 1억명 혹은 그 이상이 될 수 있습니다.
그렇다면 filteredUsers와 같이 Stream의 element가 많은 경우, 연쇄적인 filter 메서드 사용에 어떤 문제점이 발생할 수 있을까요?
문제점
가독성을 위해 연쇄적으로 filter 메서드를 사용하는 경우, 하나의 filter 메서드에 복잡한 Predicate를 사용하는 것보다 성능적으로 불리합니다.
다음 표는 동일한 필터링에 대하여 다중 필터 사용과 복잡한 조건을 사용하는 것에 대한 성능 차이 예시입니다.
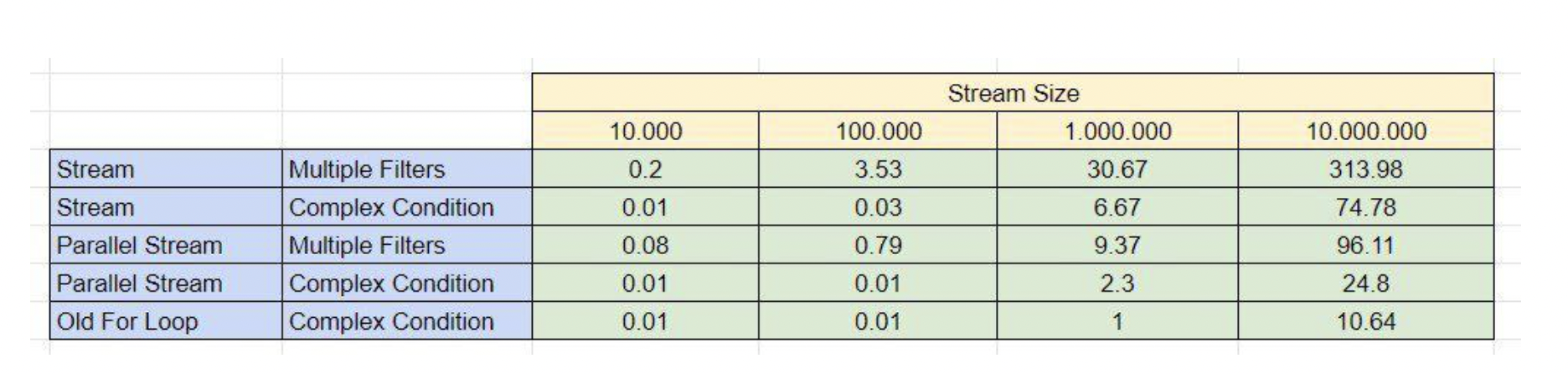 다중 필터 성능 결과
다중 필터 성능 결과
복잡한 조건의 filter 메서드 하나를 사용하는 것이, 단순한 조건의 여러 filter 메서드 하나를 사용하는 것보다 성능적으로 뛰어난 것을 확인할 수 있습니다.
위 표의 예시 처럼, 데이터가 무수히 많은 경우
Stream대신for-loop사용이 성능적으로 좋으므로 고려해야 함
Stream은 최종 연산이 호출될 때 각 element에 대하여 하나씩 파이프라인을 통과하기 때문에, 조기 탈락(Early Exit)이 성능에 영향을 미치게 됩니다.
예를 들어 filteredUsers를 구하는 과정을 살펴보면, 남자이고 이씨 성을 가졌지만 19살인 User의 경우
1
2
.filter(user -> user.gender() == Gender.MALE)
.filter(user -> user.name().startsWith("이"))
두 filter 메서드는 통과하지만,
1
.filter(user -> user.age() == 29)
마지막 filter 는 통과하지 못합니다.
따라서 조건에 부합하지 않는 element도 쓸데 없이 파이프라인의 몇 과정을 통과하기 때문에, 성능적으로 떨어지게 됩니다.
다중 필터가 아니더라도,
Stream사용 시 filter 메서드는 빨리 호출할 수록 조기 탈락을 유발하여 성능상 이점이 있음
따라서 아래 코드와 같이 복잡한 조건문을 사용하는 것이 성능에 더욱 좋은 영향을 줍니다.
1
2
3
4
5
6
7
8
public record User(String name, int age, Gender gender) {
public boolean isLeeAndMaleAtAge29() {
return name.startsWith("이")
&& gender == Gender.MALE
&& age == 29;
}
}
1
2
3
List<User> filteredUsers = userStream
.filter(User::isLeeAndMaleAtAge29)
.toList();
메서드로 추출하여 메서드 참조를 사용하면 가독성도 살리며 성능 최적화에도 도움을 줌!
그럼에도 불구하고, 여러 filter 메서드를 연쇄적으로 사용해야 한다면, 어떤 식으로 코드를 작성해야 할까요?
다중 필터 성능 문제 해결 방법
정답은 최대한 중복되지 않는, 많이 필터링 되는 조건을 앞에 배치하는 것입니다.
남자, 이씨 성, 29살이라는 조건은 각각 데이터 중복도가 다릅니다. 29살 > 이씨 성 > 남자 순서대로 데이터가 덜 중복됩니다.
따라서 filter 메서드의 순서를 아래와 같이 변경한다면,
1
2
3
4
5
List<User> filteredUsers = userStream
.filter(user -> user.age() == 29)
.filter(user -> user.name().startsWith("이"))
.filter(user -> user.gender() == Gender.MALE)
.toList();
조기 탈락되는 비율이 높은 순서로 배치되므로, 불필요한 파이프라인을 통과하지 않기 때문에 성능상으로 이점을 가집니다.